






SiFive 博客
来自 RISC-V 专家的最新洞察与深度技术解析

Dhrystone Performance Tuning on the Freedom Platform
For consumers of low-end processors, the Dhrystone benchmark can be a valuable tool for estimating performance. Due to the nature of the Dhrystone benchmark, high-end Application Processor performance is incompletely represented by a Dhrystone score. For processor providers a Dhrystone score is a commonly used metric for instruction throughput comparison in early stage evaluation.
To fairly compare Dhrystone scores, the test conditions must be published. To that end SiFive offers two Dhrystone scores for our standard cores, Legal and Best Effort. The Legal score is achieved under the conditions of the Dhrystone benchmark, laid out in the Dhrystone Compilation model and measurement "ground rules".
In this blog, I will show you how SiFive achieved Best Effort scores through the use of compiler techniques.
Achieving Best Effort
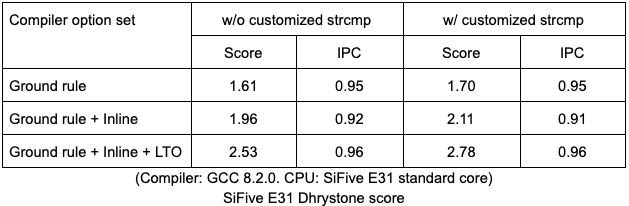
Using a SiFive E31 Standard Core, a single-issue in-order RV32IMAC core, as an example to demonstrate how a Dhrystone score can be improved dramatically. The following table a summary of the score. As expected, the E31 core reaches its peak performance of 1 IPC due to its single-issue architecture. However, the Dhrystone score varies by different compiler option sets and existence of library specific tuning. By using an aggressive compiler option set with a customized strcmp instruction, the Dhrystone score increases by 73% (1.61 to 2.78).
Dhrystone score and instruction count
Dhrystone scores are regularly represented as DMIPS/MHz using the following equation:
DMIPS/MHz = iteration/cycle*1000000/1757
The Dhrystone score is higher if fewer cycles are spent per Dhrystone iteration. One can reduce the cycle number by improving the micro-architecture (e.g., branch prediction, load latency, cache hit rate), ultimately the minimal cycle number will be limited by the instruction count.
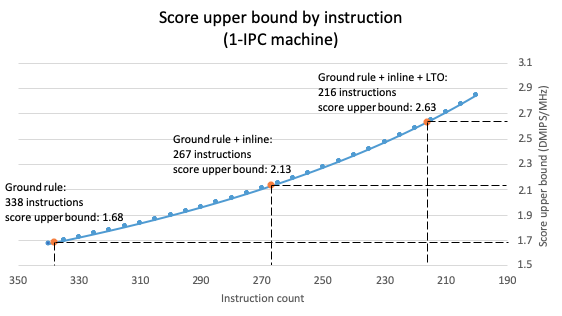
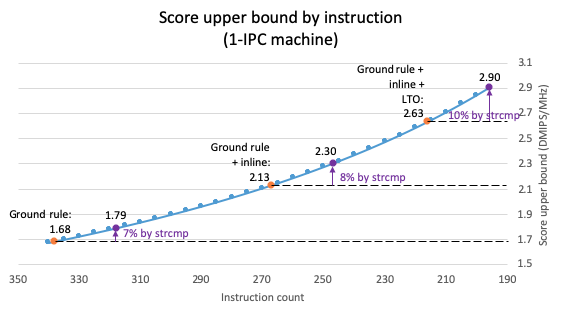
To estimate the best score by the instruction count we can assume a single-issue core maintaining peak performance (IPC=1) means that N cycles is equal to N instructions. The chart below plots the relationship of instruction number and score of a IPC-1 machine. When compiled using Legal compiler options the result is 338 instructions per iteration. This requires 338 cycles assuming peak performance, resulting in 1.68 DMIPS/MHz; 1.68 DMIPS/MHz is the best a single-issue machine can achieve for 338 instructions.
Running the Dhrystone benchmark using the Legal option, the SiFive E31 core will achieve a score of 1.61 DMIPS/Mhz, which is 96% of the maximum. Thus, a SiFive E31 core at peak performance offers IPC = 0.958.
Function Inline & Link Time Compiler Optimizations
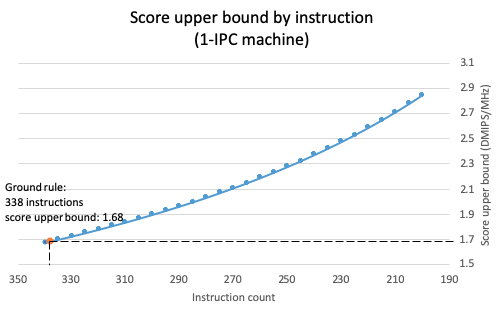
Function inlining and link time optimization (LTO) can reduce the number of instructions needed to perform the Dhrystone benchmark workload.
The chart below shows the dynamic instruction count under the 3 compiler options:
- Ground rule
- Ground rule + inline
- Ground rule + inline + LTO
Instruction count can be reduced by 21% through inline merges of functions, to reduce branches. With the application of link time optimization the instruction count can be reduced by an additional 19%. In total, the instruction are reduced by 36% purely by applying compiler optimizations.
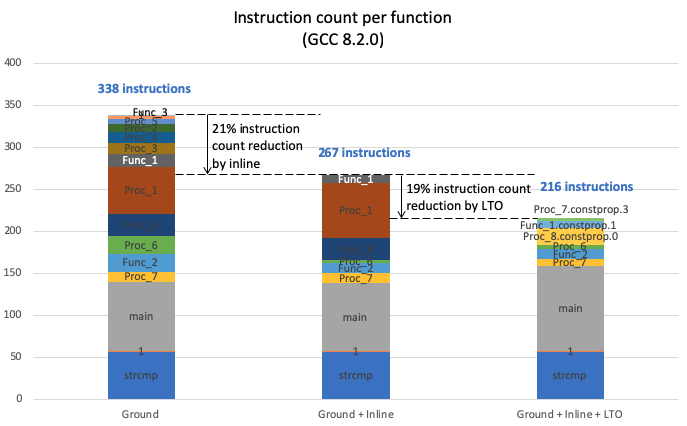
Instruction count reduction in the Dhrystone loop directly boosts the score without needing changes to the micro-architecture of the processor. In the chart below we mark the points of inline and inline + LTO. Assuming constant IPC (0.958), the score may theoretically increase 56% (1.68 to 2.63 DMIPS/Mhz). For the SiFive E31 at IPC = 0.958, the score increases 57%, from 1.61 to 2.53.
Benchmark Specific Micro-architecture Changes
The Dhrystone benchmark relies largely on standard C library functions. Analyzing the results of the previous optimizations I determined strcmp() occupies 16%, 21% and 26% of total instruction in the three compiler option sets, as represented by the below chart.
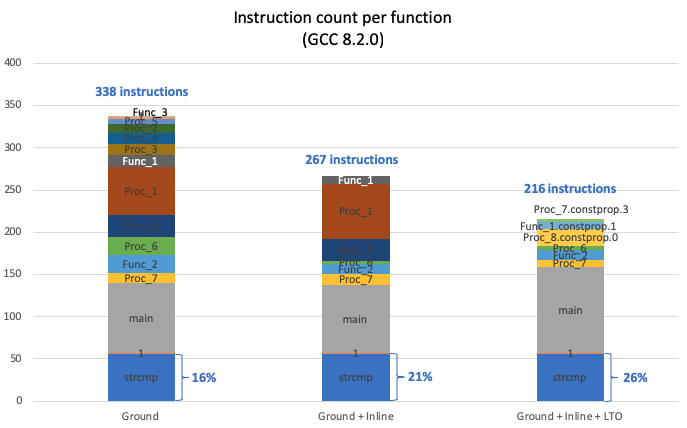
In the circumstances described above, the Dhrystone score is more affected by the implementation of the strcmp() function than the processor micro-architecture as up to 26% of the code is a single function call.
To further improve Dhrystone score, a custom instruction to improve strcmp() performance can be created to replace the strcmp() function, effectively eliminate around twenty instructions per Dhrystone iteration, based on the RISC-V newlib strcmp implementation. As the chart below shows, this can improve the score by 7%, 8%, and 10% respectively for the three options. For the SiFive E31 core (IPC = 0.958) this increases the score to 1.70, 2.11 and 2.78, respectively.
SiFive does not include a hardware implementation of strcmp, as it is unlikely to benefit many embedded processor applications. However, there may be workloads that a performance improvement based on customized instructions are worthwhile. SiFive Core Designer can help you understand the options available for configuring a core to your needs, including adding the SiFive custom instruction extension, SCIE.
Easily Reproducing SiFive Best Effort Scores
SiFive's Freedom E SDK includes the Dhrystone benchmark along with preset optimizations for the 3 compiler optimizations outlined in this blog by setting the DHRY_OPTION parameter when executing the makefile:
- Ground rule
- Ground rule + inline (DHRY_OPTION=fast)
- Ground rule + inline + LTO (DHRY_OPTION=best)
Conclusion
With this understanding of Dhrystone performance, you can now see how the score may be influenced by compiler options, and micro-architecture changes. When comparing manufacturer provided scores, the conditions of the test are important to understand so that compiler optimizations are not confused with micro-architectural advantages.
Fu-Ching Yang


Read more Insights from the RISC-V Experts

P570 Gen 3:系统视角

SiFive Performance™ P570 Gen 3 深度解析:面向下一代消费级与商用应用的高性能能效设计
