






SiFive 博客
来自 RISC-V 专家的最新洞察与深度技术解析

RISC-V Chiplets, Disaggregated Die, and Tiles
Scalable High-Performance Computing SoC Design with RISC-V
Whether you refer to the design concept as a disaggregated die, tiles, chiplets, or good ol’ multi-chip modules, a growing trend among SoC designers is making the interposer act like a ‘mainboard’ to host multiple chips. Together, these chips form a coherent whole product intended for a specific market and offer both advanced workload performance and efficiency benefits.
The technology industry is shifting to custom designs, replacing traditional general-purpose CPU and discrete accelerator platforms. Instead, the computing platform can implement application-specific processing requirements at many levels, down to the instruction set architecture (ISA). Enabling this industry shift is central to SiFive’s mission and why SiFive’s founders invented RISC-V a decade ago.
Bet on yourself with RISC-V Chiplets Based on an easily extensible open specification, the RISC-V ISA lets semiconductor companies “bet on themselves” by leveraging targeted microarchitecture development to enable a developer-friendly approach to hardware and SoC design. Because software and hardware meet at the instruction set architecture, the open specification RISC-V ISA permits freedom of adoption, vendor, extension, and customization; key traits shared with successful open technologies, such as Ethernet or Linux.
SiFive is the leading provider of RISC-V-based processors and accelerator IP and is home to the inventors of RISC-V and LLVM. As part of the RISC-V Vector extension task group, we’re excited to drive and see worldwide adoption of RISC-V Vectors as a path to creating AI and ML-focused products in markets such as AIoT, automotive, aerospace, networking, storage, hyperscale computing, and the data center. SiFive is betting on ourselves to deliver high-performance, high-quality RISC-V-based IP that will enable next-generation computing platforms.
With over 200 design wins and a billion cores shipped, technology companies can double down on that bet by working with SiFive and granting themselves the freedom to innovate.
AI in the data center and HPC
Workloads well-suited for processing on chiplets need die-to-die (D2D) communication to support the bandwidth requirements of the datasets. Combined with the advanced 2.5D packaging solutions from OpenFive, a SiFive business unit, and high performance, low power, and low latency HBM/D2D interface IP, designers can now create systems-on-chip (SoCs) that pack more compute power into smaller form factors for AI and HPC applications.
OpenFive delivers highly competitive SoCs with its spec-to-silicon design capabilities, customizable IP for AI/Cloud/HPC/storage/networking applications, and processor-agnostic, domain-specific architectures.
The OpenFive IP portfolio includes:
- Die-to-Die (D2D) interface IP for multi-die connectivity, including chiplets
- High-Bandwidth Memory subsystem (HBM2/E & HBM3)
- Low-latency, high-throughput Interlaken interface IP for chip-to-chip connectivity
- 800/400G Ethernet MAC/PCS subsystems
- USB controller IP
Architecting the Future The SiFive portfolio leads the industry as the broadest and most advanced RISC-V-based portfolio of processor IP, from the minds that created RISC-V. With leading companies implementing RISC-V-based designs for machine learning, computational vision, natural language processing, and other tasks, the need for scalable, flexible microarchitectures extends across many markets.
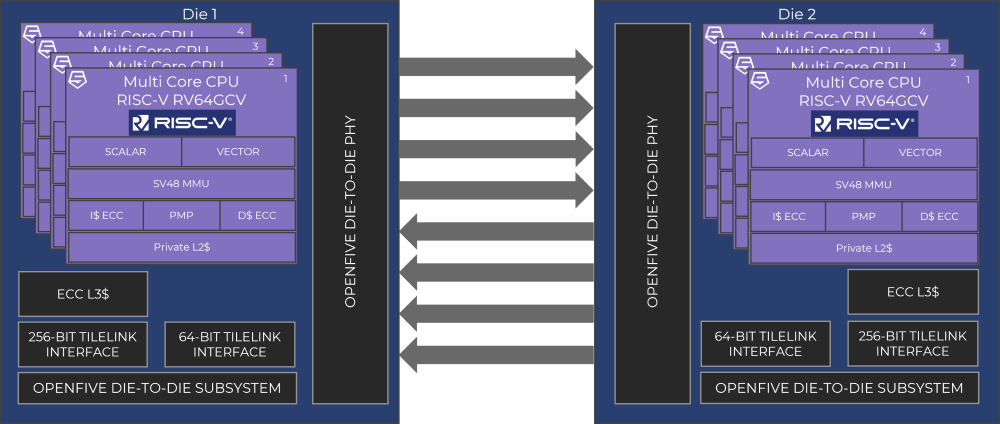
SiFive RISC-V Chiplet Architecture IP
- SiFive Performance™ family
- SiFive Performance P550
- Advanced Out-of-Order 13-stage, triple issue pipeline
- SPECInt 2006 8.65/GHz
- Highest performance commercially available RISC-V processor (1)
- SiFive Performance P270
- 8-stage, dual-issue, superscalar pipeline
- 256b Vector unit for versatile compute capabilities
- SiFive Performance P550
- SiFive Intelligence™
- SiFive Intellligence X280
- 8-stage dual-issue, superscalar pipeline
- 512-bit Vector unit with SiFive Intelligence Extensions to supercharge ML performance (2)
- Support for BF16/FP16/FP32/FP64, int8 to 64 fixed-point data types
- SiFive Intellligence X280
- SiFive Recode™
- Creates SiFive RISC-V Vector code from legacy Arm® Neon™ code to protect your existing software investment and migrate with confidence
- SiFive Essential™ family
- SiFive U/S/E class processors
- U class cores for 64-bit Linux-based application platforms
- S class cores for 64-bit embedded applications
- E class cores for 32-bit embedded applications
- SiFive U/S/E class processors
- OpenFive Die-to-Die Subsystem
- Low latency, low-power, interface supporting up to 4Tbps/mm
- Multi-cluster CPU connectivity
- Network-on-Chip interface with support for AMBA® AXI and other coherent interfaces
- Scalable, reliable links with very low BER, supporting end-to-end error correction & retransmission
- OpenFive High-Bandwidth Memory Subsystem
- 7.2Gbps speeds for HBM3 standard
SiFive enables RISC-V-powered chiplet designs for AI/ML products today, accelerating the design of new high-performance computing platforms and is leading the RISC-V uprising.
1 – SiFive Performance P550 processor measured at 8.6 SpecINT2k6/GHz by SiFive engineering, July 2021. 2 – Matrix Multiplication Kernel (int8) execution time in common benchmark measured by SiFive engineering using SiFive Intelligence X280 processor vs. RVG64GCV RISC-V Vector configuration. All trademarks referenced herein belong to their respective companies. Arm®, and Neon™ are trademarks or registered trademarks of Arm Limited (or its subsidiaries) in the US and/or elsewhere.
Chris Jones


Read more Insights from the RISC-V Experts

P570 Gen 3:系统视角

SiFive Performance™ P570 Gen 3 深度解析:面向下一代消费级与商用应用的高性能能效设计
