






SiFive 博客
来自 RISC-V 专家的最新洞察与深度技术解析

NVDLA Deep Learning Inference Compiler is Now Open Source
Designing new custom hardware accelerators for deep learning is clearly popular, but achieving state-of-the-art performance and efficiency with a new design is a complex and challenging problem.
Two years ago, NVIDIA opened the source for the hardware design of the NVIDIA Deep Learning Accelerator (NVDLA) to help advance the adoption of efficient AI inferencing in custom hardware designs. The same NVDLA is shipped in the NVIDIA Jetson AGX Xavier Developer Kit, where it provides best-in-class peak efficiency of 7.9 TOPS/W for AI. With the open-source release of NVDLA’s optimizing compiler on GitHub, system architects and software teams now have a starting point with the complete source for the world’s first fully open software and hardware inference platform.
In this blog we’ll explain the role that a network graph compiler plays in the key goal of achieving power efficiency in a purpose-built hardware accelerator, and we’ll show you how to get started by building and running your own custom NVDLA software and hardware design in the cloud.
 NVDLA Small Profile Modal
NVDLA Small Profile Modal
Compiler optimizations such as layer fusion and pipeline scheduling work well for larger NVDLA designs, providing up to a 3x performance benefit across a wide range of neural network architectures. This optimization flexibility is key to achieving power efficiency across both large network models like ResNet-50 and small network models like MobileNet.
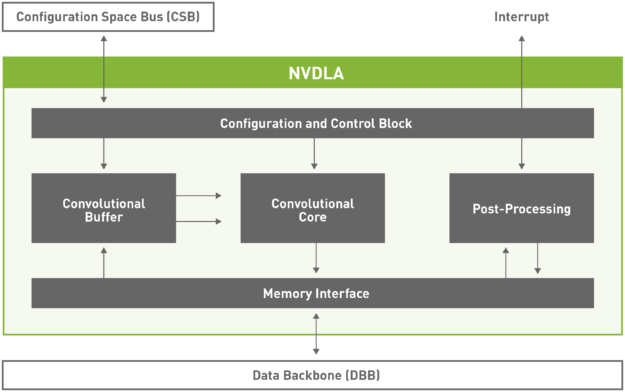
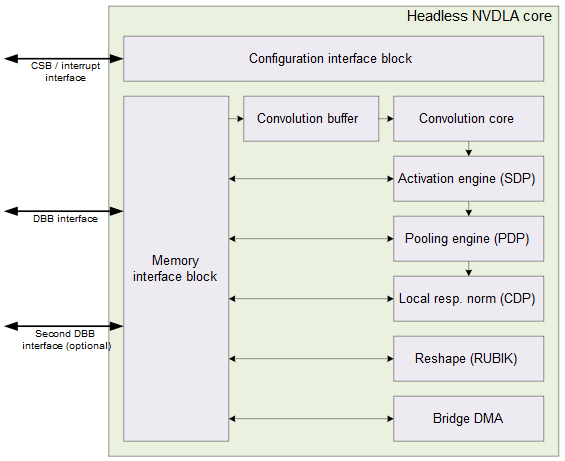
The NVDLA core hardware has six specialized hardware units which can be scheduled either concurrently or in a pipelined configuration. It also has both small and large hardware profiles. The large profile includes advanced features such as an on-chip SRAM interface and the ability to attach a microcontroller. You can find further details about NVDLA’s profiles here. The hardware architecture is modular, and it is designed to be scalable from small embedded IoT designs to large data center class chips using arrays of NVDLA units. The compiler can be tuned based on various chosen factors: the NVDLA hardware configuration, the system’s CPU and memory controller configurations, and the application’s custom neural network use cases if desired.
 NVDLA Small Profile Modal
NVDLA Small Profile Modal
Compiler optimizations such as layer fusion and pipeline scheduling work well for larger NVDLA designs, providing up to a 3x performance benefit across a wide range of neural network architectures. This optimization flexibility is key to achieving power efficiency across both large network models like ResNet-50 and small network models like MobileNet.

For smaller NVDLA designs, compiler optimizations such as memory tiling are critical for power efficiency. Memory tiling enables a design to balance on-chip buffer usage between weight and activation data, and so minimizes off-chip memory traffic and power consumption.
Furthermore, users are free to create fully customized layers tuned for their own specialized use cases or experiment with the latest cutting-edge algorithms published in research.
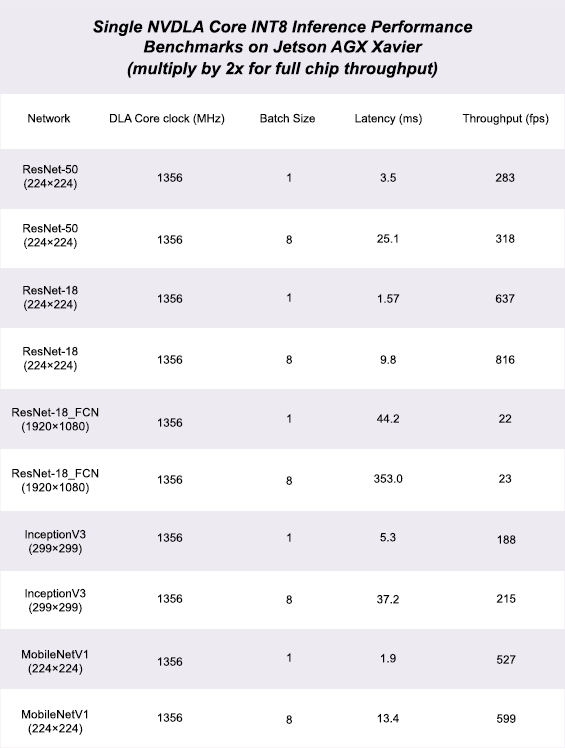
Users can gauge the expected performance of the default NVDLA large profile model based on the performance numbers below. Measurements were captured using one of the two NVDLA cores on a Jetson AGX Xavier Developer Kit.
Design in the Cloud with RISC-V and FireSim on AWS
With this compiler release, NVDLA users have full-access to the software and hardware source needed to integrate, grow, and explore the NVDLA platform. One of the best ways to get started is to dive right in with object detection using YOLOv3 on NVDLA with RISC-V and FireSim in the cloud.
To get hands on with FireSim-NVDLA, follow the FireSim directions until you are able to run a single-node simulation. While following the step-by-step instructions, verify that you are using the firesim-nvdla repository during the “Setting up the FireSim Repo” section as shown below:
git clone https://github.com/CSL-KU/firesim-nvdla
cd firesim-nvdla
./build-setup.sh fast
Once your single-node simulation is running with NVDLA, follow the steps in the Running YOLOv3 on NVDLA tutorial, and you should have YOLOv3 running in no time.
NVIDIA is excited to collaborate with innovative companies like SiFive to provide open-source deep learning solutions.
 SiFive running Deep Learning Inference using NVDLA
SiFive running Deep Learning Inference using NVDLA
"We are incredibly excited to see NVIDIA leading efforts developing the open-source Machine Learning ecosystem," said Yunsup Lee, CTO/co-founder of SiFive and co-inventor of RISC-V. “SiFive first demonstrated NVDLA running on the SiFive Freedom Platform a year ago, and the new performance-optimized open-source NVDLA compiler further enables SiFive to create domain-specific optimized SoC designs ready for the modern compute needs of AI in the IoT Edge.”
Stay Plugged In
- Sign up on the nvdla.org website to receive NVDLA news and announcements
- Download the latest open-source release of NVDLA
- Give NVDLA a try today with YOLOv3 on FireSim-NVDLA
- Get involved with the NVDLA community on GitHub
- Feel free to contact the NVIDIA NVDLA team through e-mail


Read more Insights from the RISC-V Experts

P570 Gen 3:系统视角

SiFive Performance™ P570 Gen 3 深度解析:面向下一代消费级与商用应用的高性能能效设计
